ViT-CoMer: Vision Transformer with Convolutional Multi-scale Feature Interaction for Dense Predictions
The official implementation of the CVPR2024 paper "Vision Transformer with Convolutional Multi-scale Feature Interaction for Dense Predictions"
Paper | ViT-CoMer知乎解读 | 检测排名图paperwithcode |分割排名图paperwithcode|

- We propose a novel dense prediction backbone by combining the plain ViT with CNN features. It effectively
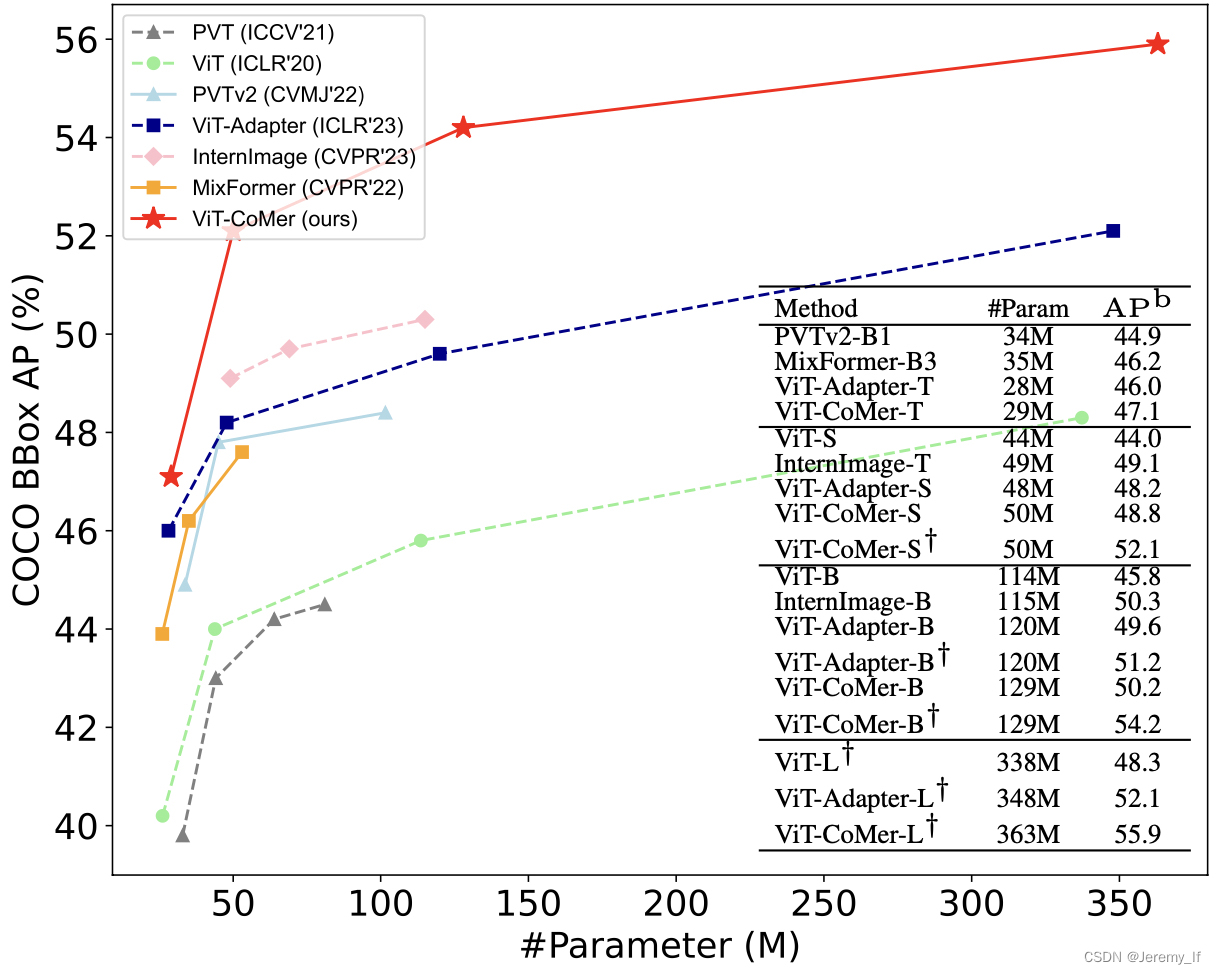
leverages various open-source pre-trained ViT weightsand incorporates spatial pyramid convolutional features that address the lack of interaction among local ViT features and the challenge of single-scale representation. - ViT-CoMer-L achieves
64.3% APon COCO val2017 without extra training data, and62.1% mIoUon ADE20K val.
We present a plain, pre-training-free, and feature-enhanced ViT backbone with Convolutional Multi-scale feature interaction, named ViT-CoMer, which facilitates bidirectional interaction between CNN and transformer. Compared to the state-of-the-art, ViT-CoMer has the following advantages: (1) We inject spatial pyramid multi-receptive field convolutional features into the ViT architecture, which effectively alleviates the problems of limited local information interaction and single-feature representation in ViT. (2) We propose a simple and efficient CNN-Transformer bidirectional fusion interaction module that performs multi-scale fusion across hierarchical features, which is beneficial for handling dense prediction tasks.