High-Performance Column-Oriented Data Streaming Library
Spinel is an efficient, column-oriented data streaming framework designed for real-time tabular data processing. Built for both embedded and distributed architectures, Spinel enables efficient data transformations with minimal memory overhead and maximum throughput.
- Column-Oriented Storage: Optimized memory layout with superior cache locality and reduced fragmentation
- Reference-Passing Design: Zero-copy data access through pointer-like references to source rows
- Single-Pass Processing: Data flows directly through transformations without intermediate copies
- Minimal Memory Footprint: Array-based storage eliminates object overhead
- Event-Driven Architecture: Push-based updates with minimal latencies
- Live Data Streaming: WebSocket and gRPC integration for real-time client updates
- Incremental Processing: Only changed data is processed and transmitted
- Embeddable Library: Seamlessly integrate into existing applications (Kafka, Spring Boot, microservices)
- Multi-Process Communication: Built-in IPC operators for distributed systems
- Protocol Agnostic: Support for WebSockets, gRPC, and custom protocols
Perfect for financial trading platforms, IoT monitoring, and business intelligence dashboards requiring:
- Live market data feeds with sub-millisecond updates
- Real-time KPI monitoring and alerting
- Interactive data exploration with instant filtering and aggregation
- Multi-user concurrent access with efficient resource utilization
Ideal for microservices architectures and data processing workflows:
- High-throughput ETL pipelines with complex joins and transformations
- Real-time analytics engines processing streaming data
- Event sourcing systems with live projections
- Inter-service communication with structured data contracts
Seamlessly embed into existing applications. All transforms and data processing are just plain Java, and require no other infrastructure. Your topology can be totally contained in your process, or you can connect topologies across processes.
You can also author your own operators by conforming to the TransformInput and TransformOutput interfaces.
Event flow into an Operator begins with a Schema update, which describes the data to the operator, but also is how the operator will access the data. Data in Spinel is typically column-oriented and accessible through the Field interfaces.
+-----------+ +-----------+
| order | | product |
| table | | table |
+---------+-+ +-+---------+
| |
+---v---------v---+
| join |
| (on product_id) |
+--------+--------+
| |
+------v------+ +------v------+
| filter | | group-by |
| (user) | | (category) |
+-------------+ +-------------+
| |
+-------v-------+ +-------v-------+
| grpc sink | | web-socket |
| | | client |
+---------------+ +---------------+
Data Storage & Access
- KeyedTables: Indexed tables by primitive types (int, long, string)
- Column-Oriented Fields: Each field stored in optimized arrays
Transformations
- Filter: High-performance row filtering with custom predicates
- Join: Inner/outer joins with configurable key handling strategies
- GroupBy: Real-time aggregations with incremental updates
- Projection: Field selection, aliasing, reordering, and calculated fields
- Union: Merge multiple data streams into unified output
- Conflation: Reduce update frequency to conserve CPU and network bandwidth
- Projection: Projections for calculated fields, field selection, and aliasing
Integration & Communication
- Subscription Management: Multi-client subscription handling
- Protocol Adapters: WebSocket, gRPC, NATS.io, and custom protocol support
Memory Efficiency
- Column-oriented storage reduces memory fragmentation
- Reference-passing eliminates unnecessary data copying
- Compact, array-based field indexing
Processing Speed
- Single-pass transformations minimize CPU cycles
- Cache-friendly data access patterns
Network Efficiency
- Protocol Buffer encoding for minimal bandwidth usage
- Incremental updates reduce network traffic by 90%
- Built-in conflation prevents message flooding
NATS.io Integration (NATS Examples)
Tables can be emitted to and sourced from NATS KV Buckets. There are two varieties of sourcing from a KV bucket:
You control the deserialization of the bucket's entries.
KeyValue mdKeyValue = connection.keyValue(mdBucketName);
mdAdapter = NatsKvAdapterBuilder.natsKvAdapter()
// custom handler for decoding and writing data to schema fields
.updateHandler(new MdKeyValueHandler())
// adapter must know the schema ahead of time
.addFields(marketDataBucketFields())
.eventLoop(eventLoop)
.build();
mdKeyValue.watchAll(mdAdapter.keyValueWatcher());The framework encodes the schema into the bucket allowing some flexibility with schema changes between publisher and consumer
// Server/Publisher side
Connection connection = Nats.connect(options);
KeyValue ordersKeyValue = connection.keyValue(bucketName);
NatsKvSink sink =
NatsKvSinkBuilder.natsKvSink()
.keyValueBucket(ordersKeyValue)
.subjectBuilder(
FieldSequenceNatsSubjectBuilder.fieldSequenceNatsSubjectBuilder(
List.of("InstrumentId", "OrderId")))
.build();
Connector.connectInputToOutput(sink, orders);
// Client/Consumer side
KeyValue ordersKeyValue = connection.keyValue(bucketName);
NatsKvSource orderSource = NatsKvSourceBuilder.natsKvSource().eventLoop(eventLoop).build();
ordersKeyValue.watchAll(orderSource.keyValueWatcher());@Configuration
public class TopologyBuilder {
private final RegisteredOutputsTable outputs = RegisteredOutputsTable.registeredOutputsTable();
private final EventLoop eventLoop;
private final DefaultSubscriptionProvider subscriptionProvider;
public TopologyBuilder() {
this.eventLoop = new DefaultEventLoop(r -> { return new Thread(r, "server-thread"); });
// .... setup transforms and register them in the RegisteredOutputsTable
outputs.register("orders", orders);
outputs.register("instruments", instruments);
outputs.register("order-view", join.output());
subscriptionProvider = DefaultSubscriptionProvider.defaultSubscriptionProvider(outputs);
}
@Bean
HandlerMapping handlerMapping() {
final var mapping =
new SimpleUrlHandlerMapping(
Map.of("/ws/spinel", new SpinelWebSocketHandler(subscriptionProvider, eventLoop)));
mapping.setOrder(-1);
return mapping;
}
@Bean
public OutputRegistry registry() {
return outputs;
}
...Use Spinel transformations to operate over state stores.
// Create a keyed table
IntIndexedStructTable<Order> orders = intIndexedStructTable(Order.class).build();
Order facade = orders.createFacade(); // reusable facade
// Add data
orders.beginAdd(1, facade)
.setInstrumentId(100)
.setQuantity(500)
.setPrice(25.50);
orders.endAdd();
// Query data
int row = orders.lookupKeyRow(1);
orders.moveToRow(facade, row);
double price = facade.getPrice(); // 25.50// Create a join between orders and instruments
Join orderView = JoinBuilder.lookupJoin("order-view")
.inner()
.joinOn(List.of("InstrumentId"), List.of("InstrumentId"), 10)
.build();
// Connect data sources
Connector.connectInputToOutput(orderView.leftInput(), orders);
Connector.connectInputToOutput(orderView.rightInput(), instruments);
// Register for real-time subscriptions
OutputRegistry registry = RegisteredOutputsTable.registeredOutputsTable();
registry.register("enriched-orders", orderView.output());Spinel offers two powerful approaches for building data processing topologies:
The TransformBuilder provides a fluent, declarative API for complex topologies:
TransformBuilder transform = TransformBuilder.transform();
transform.intIndexedStructTable(Order.class)
.then()
.filter("open-orders").where("open == true")
.then()
.groupBy("open-by-instrument")
.groupByFields("InstrumentId")
.addAggregation(sumToInt("Quantity", "TotalQuantity"))
.addAggregation(sumToInt("Notional", "TotalNotional"));
transform.build();Use individual *Builder classes for fine-grained control:
// Create components explicitly
IntIndexedStructTable<Order> orders = intIndexedStructTable(Order.class)
.initialSize(1000)
.chunkSize(256)
.build();
Filter openOrders = FilterBuilder.filter("open-orders")
.where("open == true")
.build();
GroupBy byInstrument = GroupByBuilder.groupBy("open-by-instrument")
.groupByFields("InstrumentId")
.addAggregation(sumToInt("Quantity", "TotalQuantity"))
.addAggregation(sumToInt("Notional", "TotalNotional"))
.build();
// Connect manually for precise control
Connector.connectInputToOutput(openOrders, orders);
Connector.connectInputToOutput(byInstrument, openOrders);// Backend: WebSocket streaming
@Bean
public WebSocketHandler spinelHandler(OutputRegistry registry) {
return new SpinelWebSocketHandler(
defaultSubscriptionProvider(registry),
eventLoop
);
}
// Frontend: JavaScript client
const client = new SpinelClient();
await client.connect();
const subscription = client.subscribe('live-orders');
subscription.attachInput(new class extends TransformInput {
rowsAdded(rows) {
// Update dashboard in real-time
updateOrdersTable(rows);
}
});// Server: Expose data via gRPC
RegisteredOutputsTable registry = RegisteredOutputsTable.registeredOutputsTable();
registry.register("market-data", marketDataTable);
GrpcService service = GrpcServiceBuilder
.grpcService(defaultSubscriptionProvider(registry), eventLoop)
.build();
// Client: Subscribe to real-time updates
GrpcClient client = GrpcClientBuilder
.grpcClient(channel, eventLoop)
.build();
GrpcSource marketData = GrpcSourceBuilder
.grpcSource(client, "market-data")
.subscription(SubscriptionConfig.subscriptionConfig("market-data").defaultAll().build())
.build();Core Examples (examples/)
- Table Operations: Basic CRUD operations and data modeling
- Filtering: Dynamic filtering with client-server communication
- gRPC Integration: Multi-server distributed data processing
- Subscriptions: Permission-based data access
Spring Boot Integration (spring-examples/) (In development)
Real-time dashboard example with:
- WebSocket streaming to browser clients
- Protocol Buffer encoding for efficiency
- Live order and instrument data with joins
- Interactive filtering and subscription management
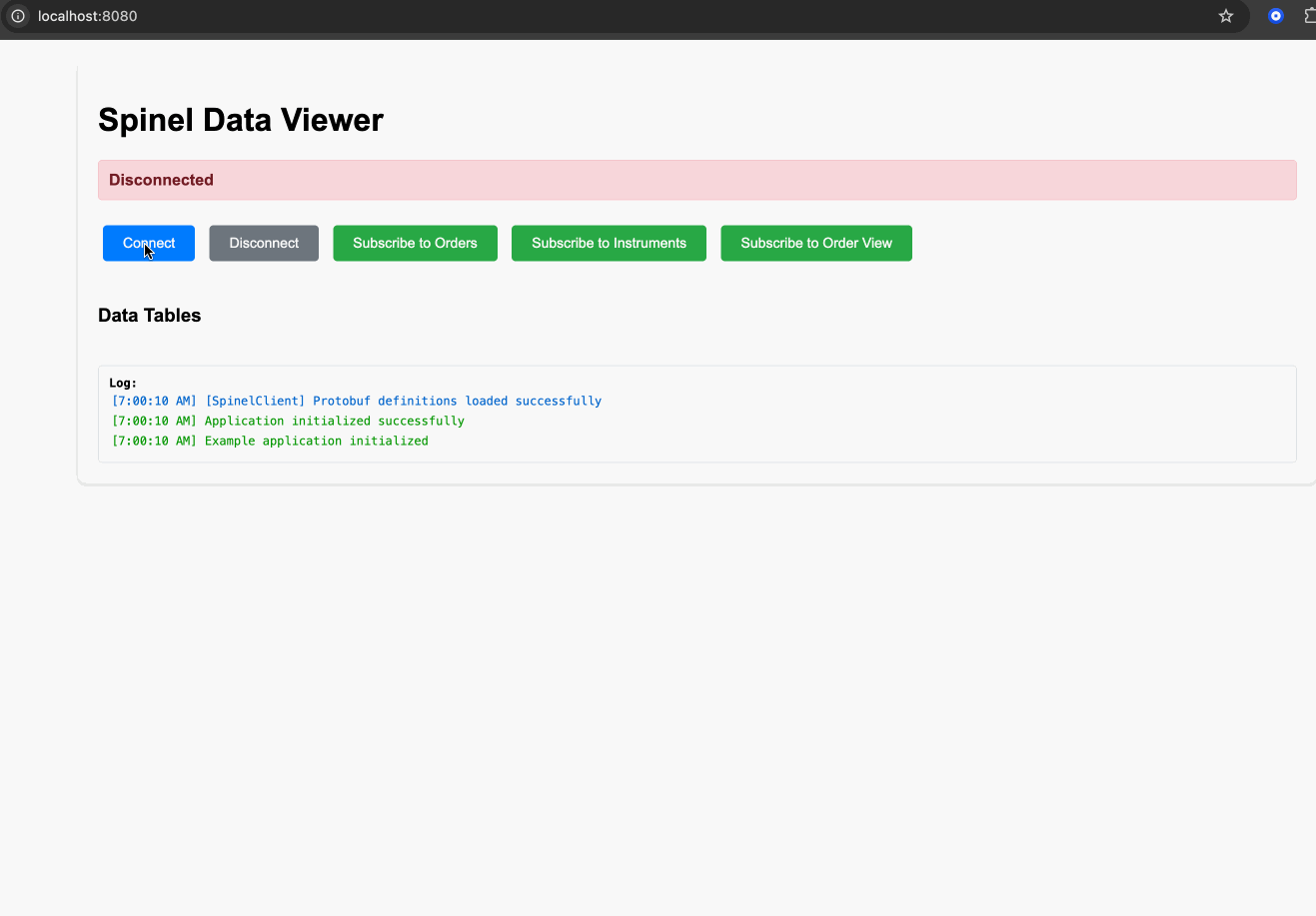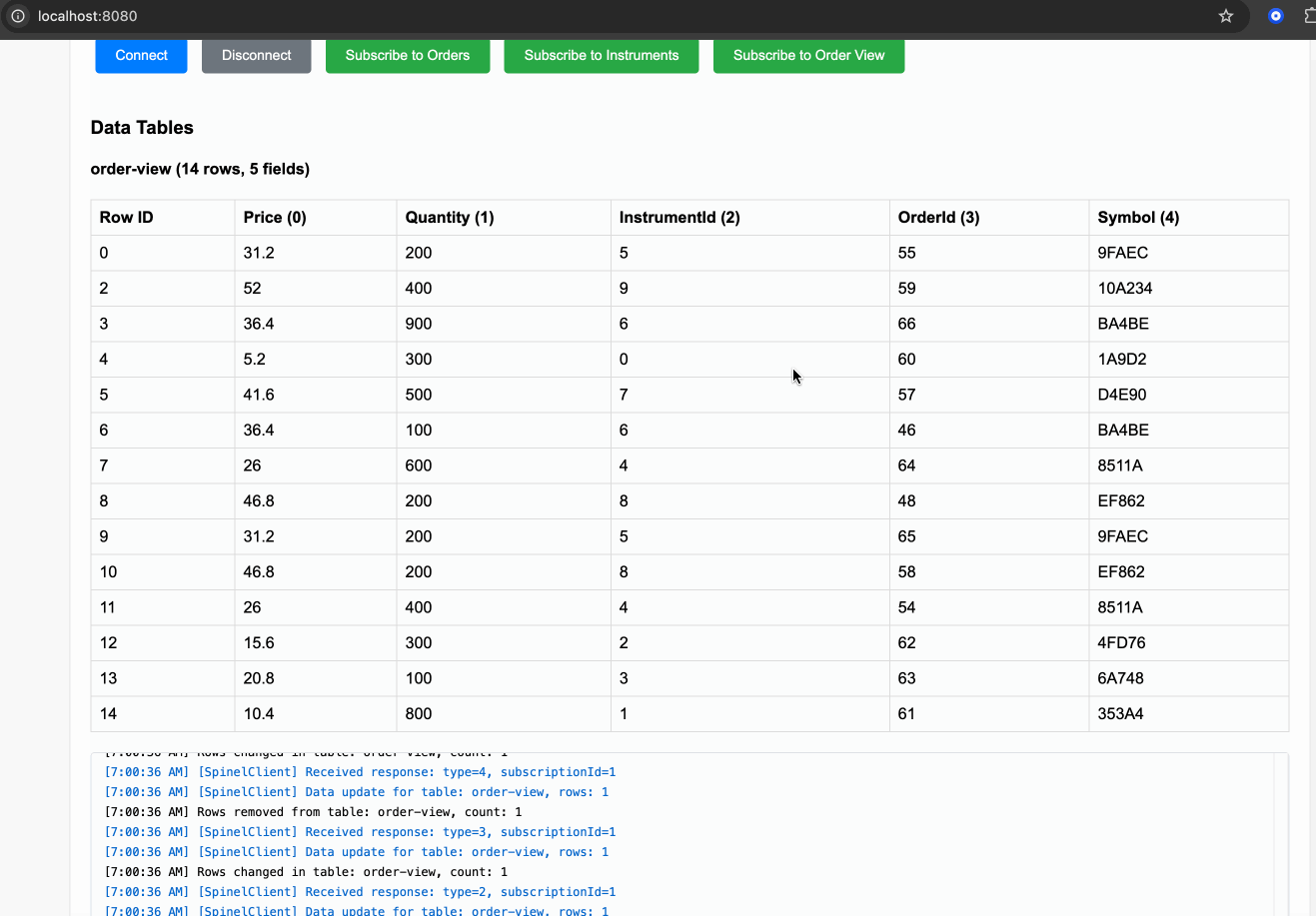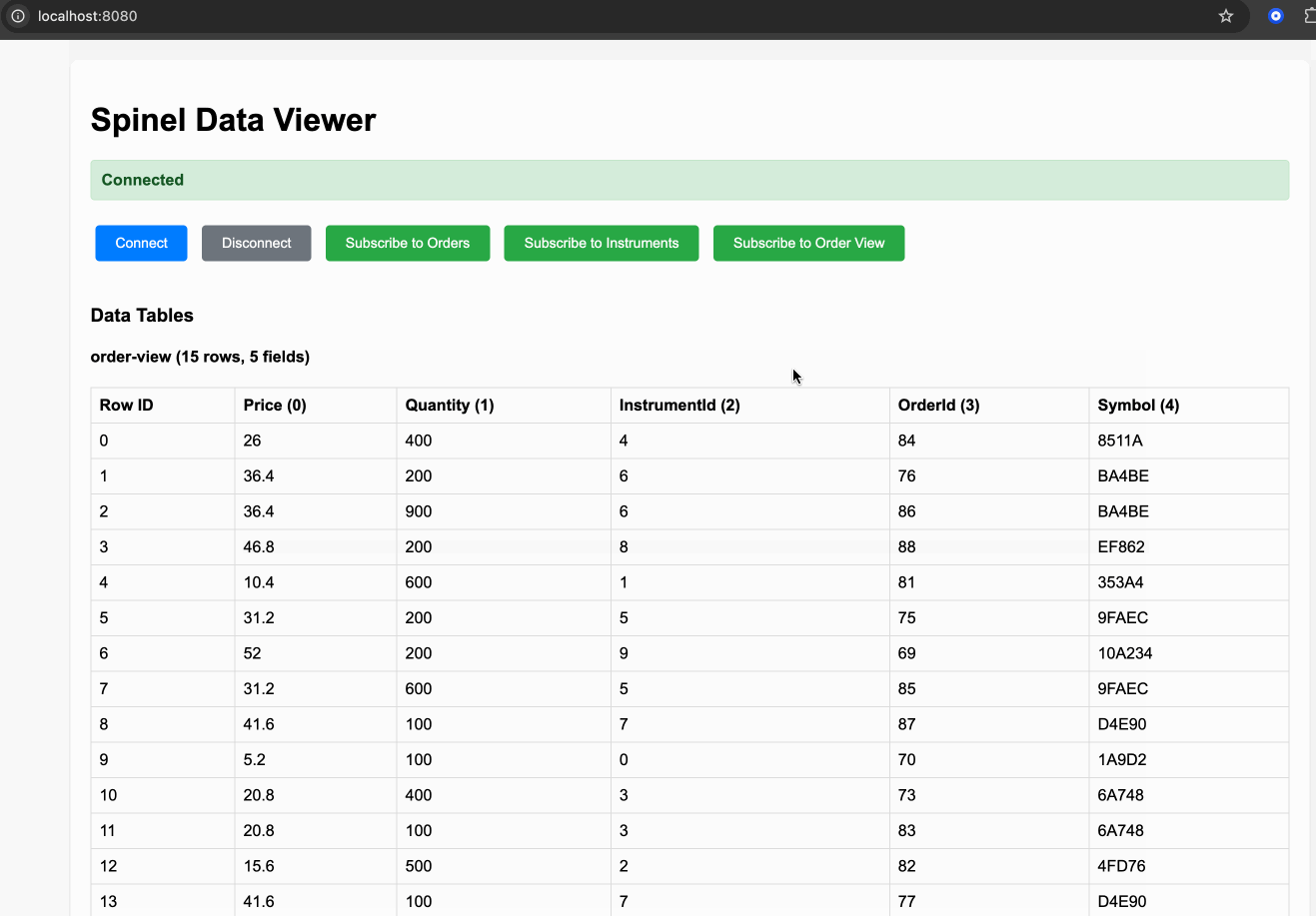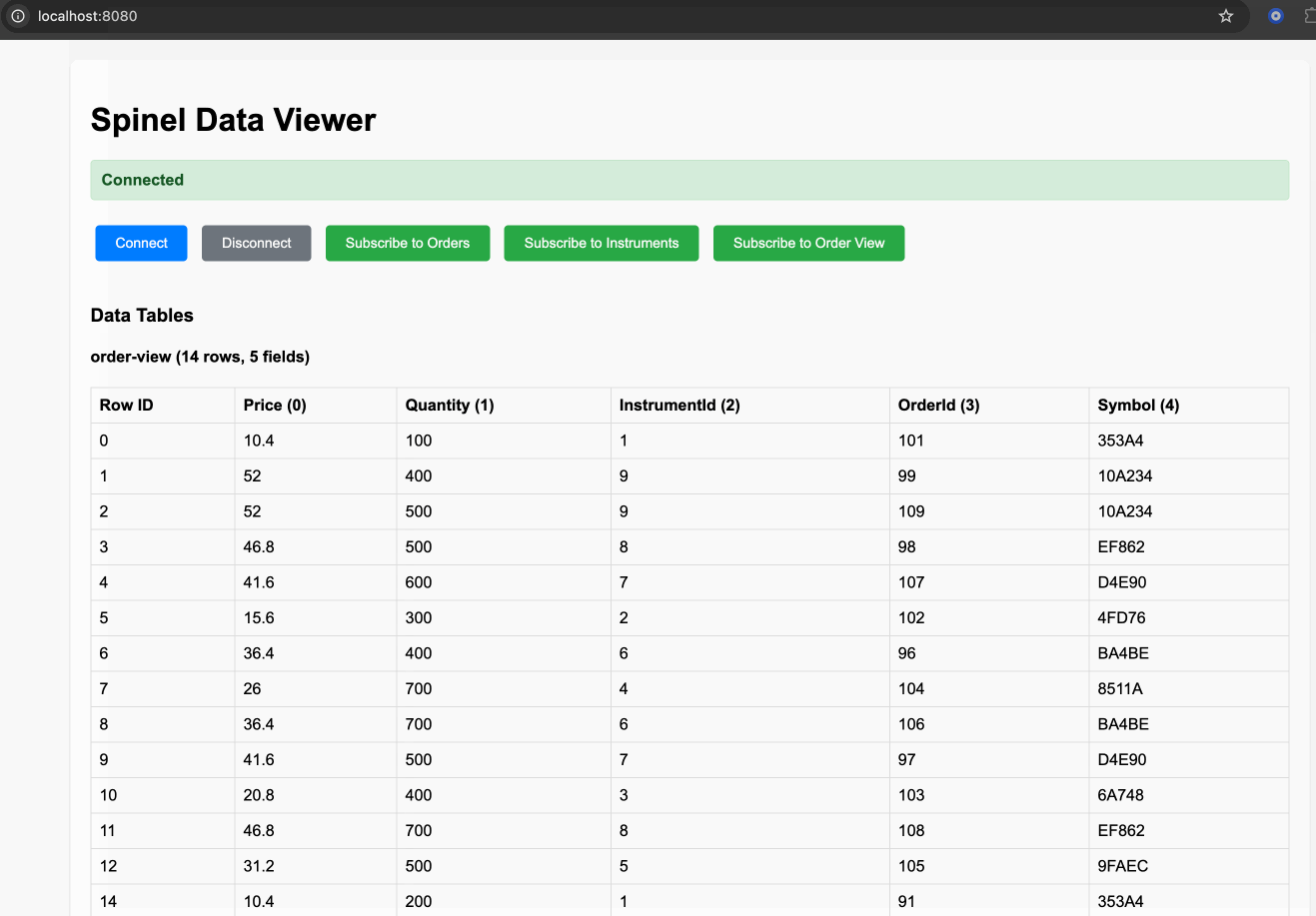
Run the example:
./gradlew :spring-examples:bootRun
# Open http://localhost:8080Perfect For:
- Real-time financial trading platforms
- IoT sensor data aggregation and monitoring
- Live business intelligence dashboards
- High-frequency data processing pipelines
- Event sourcing with live projections
- Microservices requiring structured data exchange
-
Add Spinel to your project:
implementation 'com.bytefacets:spinel:+' implementation 'com.bytefacets:spinel-grpc:+' // For gRPC integration
-
Define your data model:
// This is the reflection-based way to define a model for a table. The reflection is only performed // on setup. There is also a non-reflection based method to declare a table's fields. interface Order { int getOrderId(); // getter-only for table that is keyed by this field String getSymbol(); Order setSymbol(String value); int getQuantity(); Order setQuantity(int value); double getPrice(); Order setPrice(double value); }
-
Create and populate tables:
IntIndexedStructTable<Order> orders = intIndexedStructTable(Order.class).build(); Order facade = orders.createFacade(); orders.beginAdd(1, facade) .setSymbol("AAPL") .setQuantity(100) .setPrice(150.25); orders.endAdd(); orders.fireChanges();
-
Register outputs for client connections to this server:
RegisteredOutputsTable registry = RegisteredOutputsTable.registeredOutputsTable()e; registry.register("orders", orders); // WebSocket, gRPC, or custom protocol integration
- Spring Examples: Complete real-time dashboard example
- Core Examples: Fundamental usage patterns
Ready to build high-performance real-time applications? Start with the Spring Examples for a complete working dashboard, or explore the Core Examples for specific integration patterns.