这篇文档会介绍一些重要的工具
无论你以后从事什么计算机相关的工作,一定会用到git,它是一个很重要的工具。校园项目,公司实习,真正的就业,都离不开git
Git 是一个 版本控制系统。它就像是一个强大的记录本,用来记录你对一个文件或者项目所做的每一个修改。通过 Git,你可以:
下载:可以下载他人的开源项目
保存:你工作的每一步,不怕丢失。
回溯:到过去的版本,查看曾经的工作成果。
与别人协作:多人可以一起做同一个项目,而 Git 会帮助你们管理每个人的修改。
GitHub 是一个基于 Git 的平台,它就像是一个云端仓库,可以让你存放代码、分享和协作。就像是你可以把本地保存的文件上传到 Google Drive 或 百度网盘 一样,GitHub 提供了一个在线存储的地方,方便多人一起管理和修改代码。你可以从中找到很多优秀的项目,比如你们下个学期的C++课程设计。
点击这里下载安装包
之后双击安装,如果你第一次接触git,就一路点击next之后安装。如果你对git有一定了解,可以选择自己想要的设置
之后需要把git添加到系统环境变量,找到你安装git的目录,以此选择Git-cmd,然后把完整的地址复制下来添加到系统环境变量,如下图:
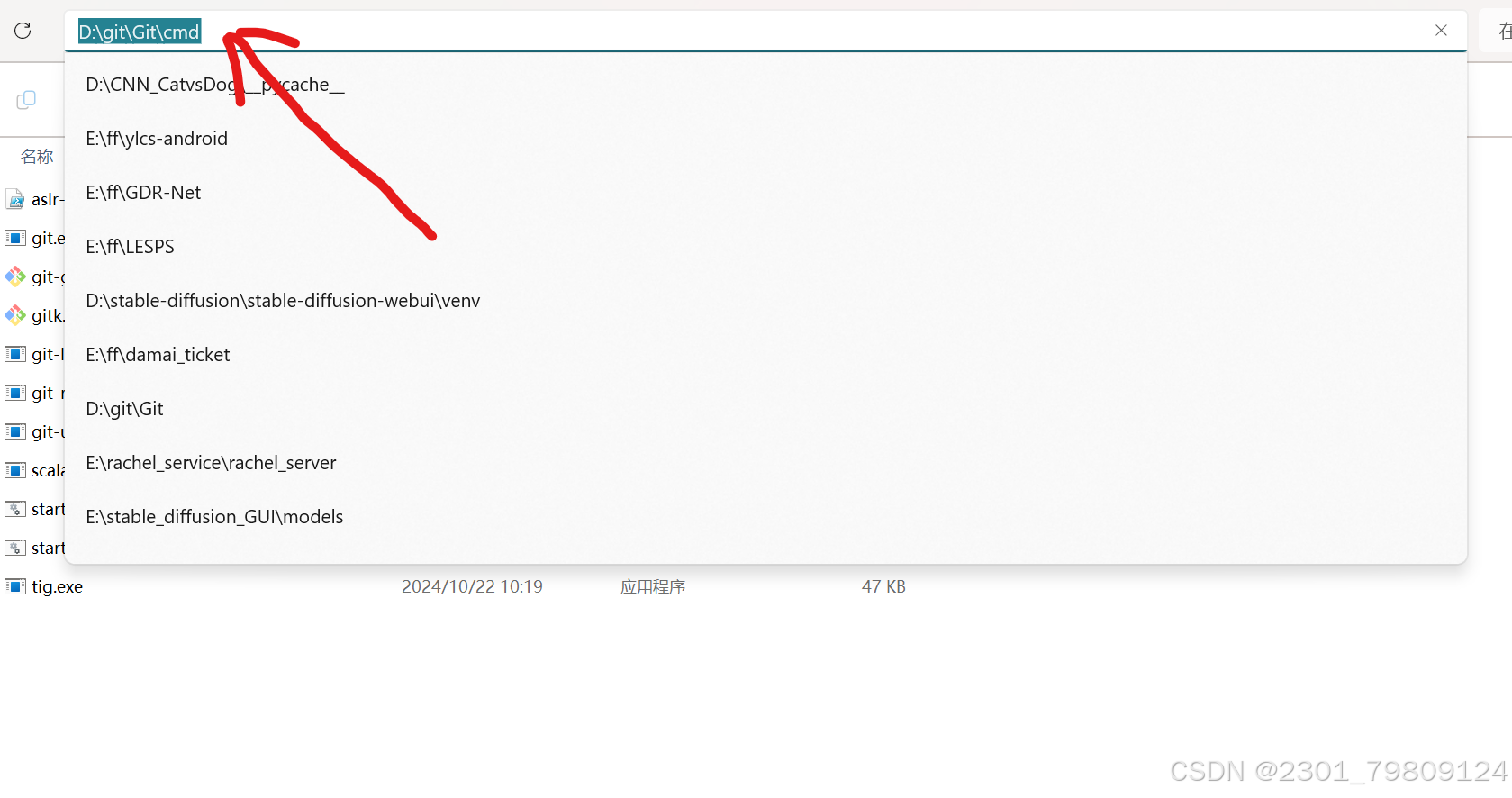
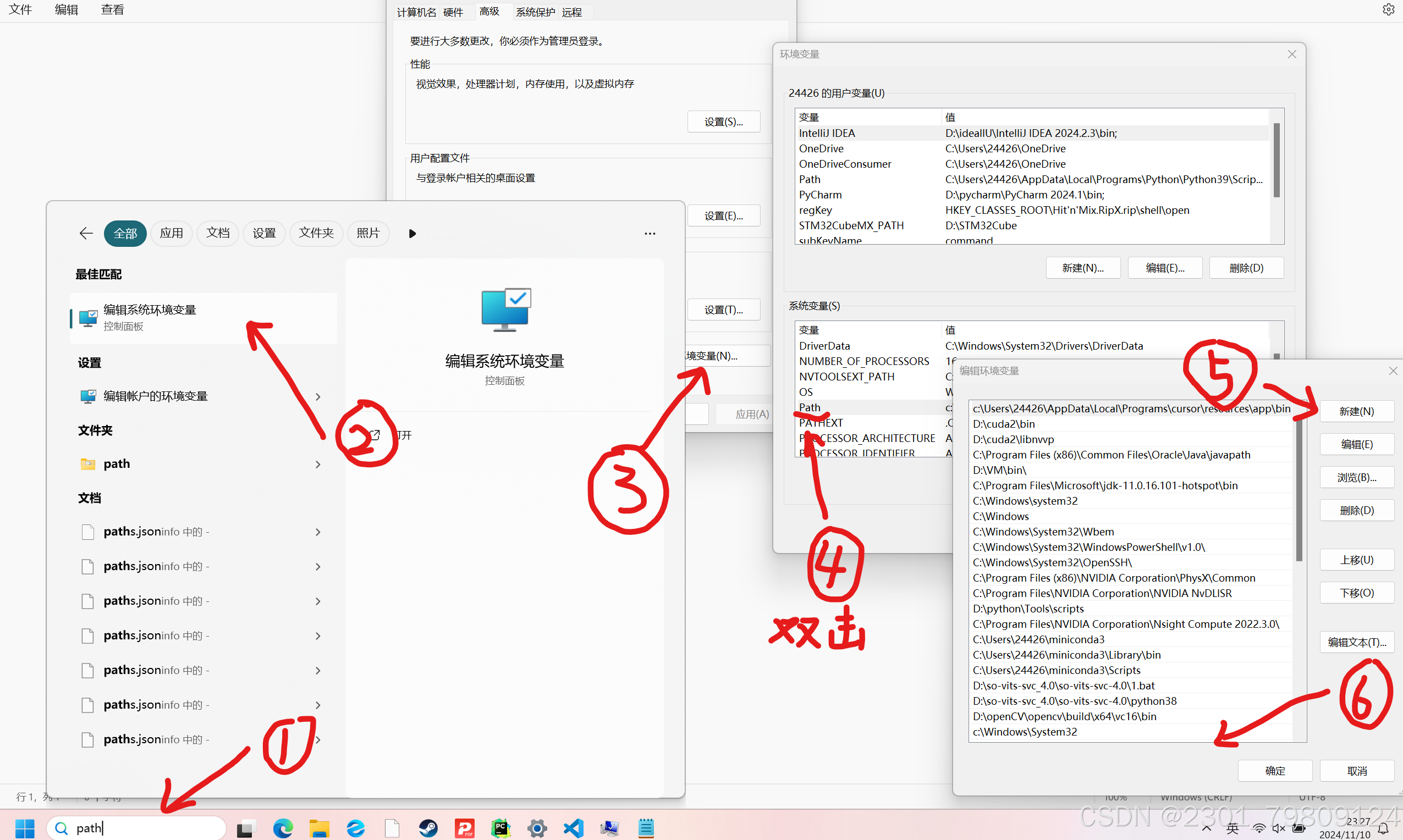
随后在控制台输入git,如果你得到以下结果,说明你的git已经配置完成
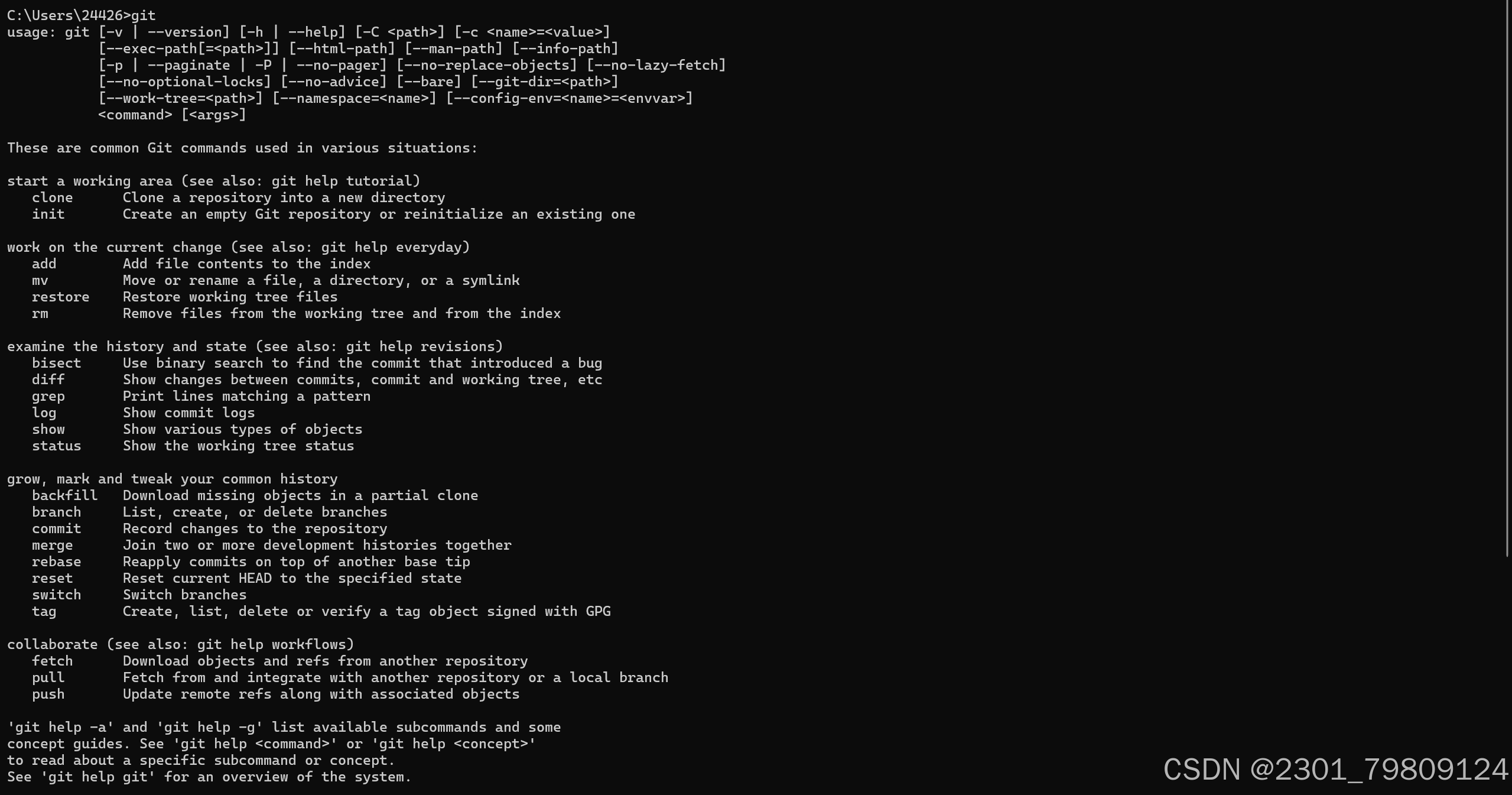
更多关于git的知识请查看官方文档
(如果你还不知道GPU,CPU,显卡,内存这些概念,请认真学习<计算机科学概论>这门大一上学期的课,或者务必请教这门课的老师!!)
在深度学习中,模型训练需要处理大量数据,且计算量非常非常大。如果只用电脑的 CPU 来完成这些计算,速度会非常慢,可能需要好几天甚至更长时间。而 GPU在架构设计上的多核并行处理机制在进行tensor运算的时候可以极大加快计算速度(我希望大家对于这里的”极大“有个具象的认识:原本使用CPU需要2个小时的训练任务放到GPU上只需要6分钟!!!)所以GPU加速是必要的
为了让深度学习框架(比如 PyTorch 或 TensorFlow)能有效利用 GPU 的强大性能,需要安装一套 GPU 加速工具链,包括 NVIDIA 驱动(nvidia-driver)、CUDA 工具包(CUDA Toolkit) 和 cuDNN(CUDA 深度神经网络库)。它们各自的作用如下:
NVIDIA 驱动 (nvidia-driver): 就像是电脑上的“驱动程序”,负责让操作系统能识别 GPU 并与之通讯。安装驱动后,系统才知道 GPU 的存在,并可以发送任务给它处理。没有驱动,电脑就无法利用 GPU 的任何功能。
CUDA 工具包 (CUDA Toolkit): CUDA 是 NVIDIA 专门为 GPU 编程开发的一套软件框架。它提供了基本的计算工具,让深度学习框架能够利用 GPU 进行加速运算。CUDA 工具包包含许多数学计算的底层功能,比如矩阵运算、向量运算,这些都是深度学习模型训练中常用的运算。
cuDNN (CUDA 深度神经网络库): cuDNN 是一个专门为深度学习设计的加速库。它包含了各种优化好的深度学习基础算法,比如卷积、池化、激活函数等。cuDNN 是在 CUDA 的基础上进一步优化的,让深度学习模型的训练速度更快。
下面我们来安装他们
如果你的电脑用的是Windows操作系统,一般电脑会默认自动安装nvidia驱动,当然也不排除个别情况下商家偷懒
输入以下命令查看你的显卡状态
nvidia-smi
正常情况下会显示如下图片,我们可以从中发现一些有用的信息,如下图:
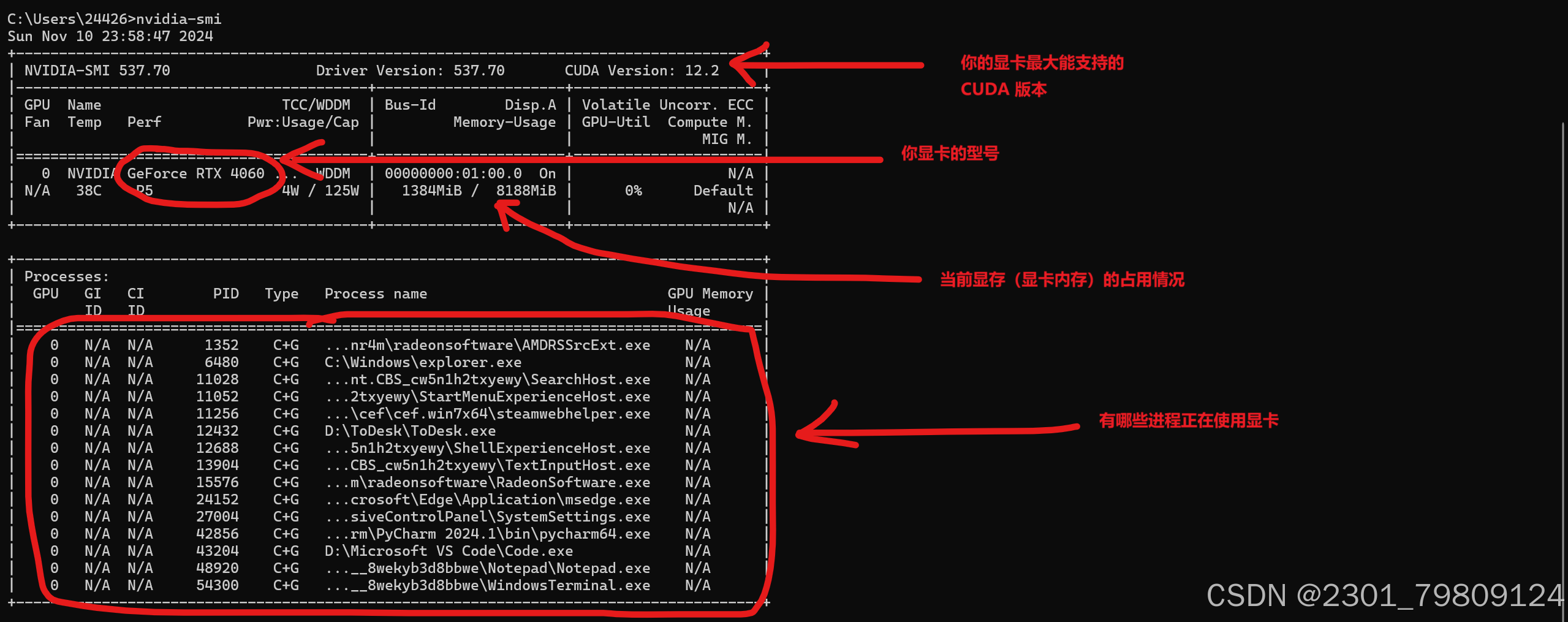
如果没有,请根据你购买电脑时候商家给的显卡信息,去英伟达官网搜索相应型号的驱动下载,或者联系电脑卖家给你安装
上面的图片中,显示了你的显卡最大支持的CUDA版本,在选择的时候不要超过这个版本 在nvidia官网选择你想要的版本,注意:考虑到与pytorch兼容,只有11.8,12.1,12.4三个版本可以选择
我个人推荐CUDA toolkit 11.8,这是目前最稳定的版本,下载链接在下面 https://developer.download.nvidia.com/compute/cuda/11.8.0/local_installers/cuda_11.8.0_522.06_windows.exe
下载安装后,别忘记把以下目录添加到环境变量,具体操作如part 1里添加环境变量的操作
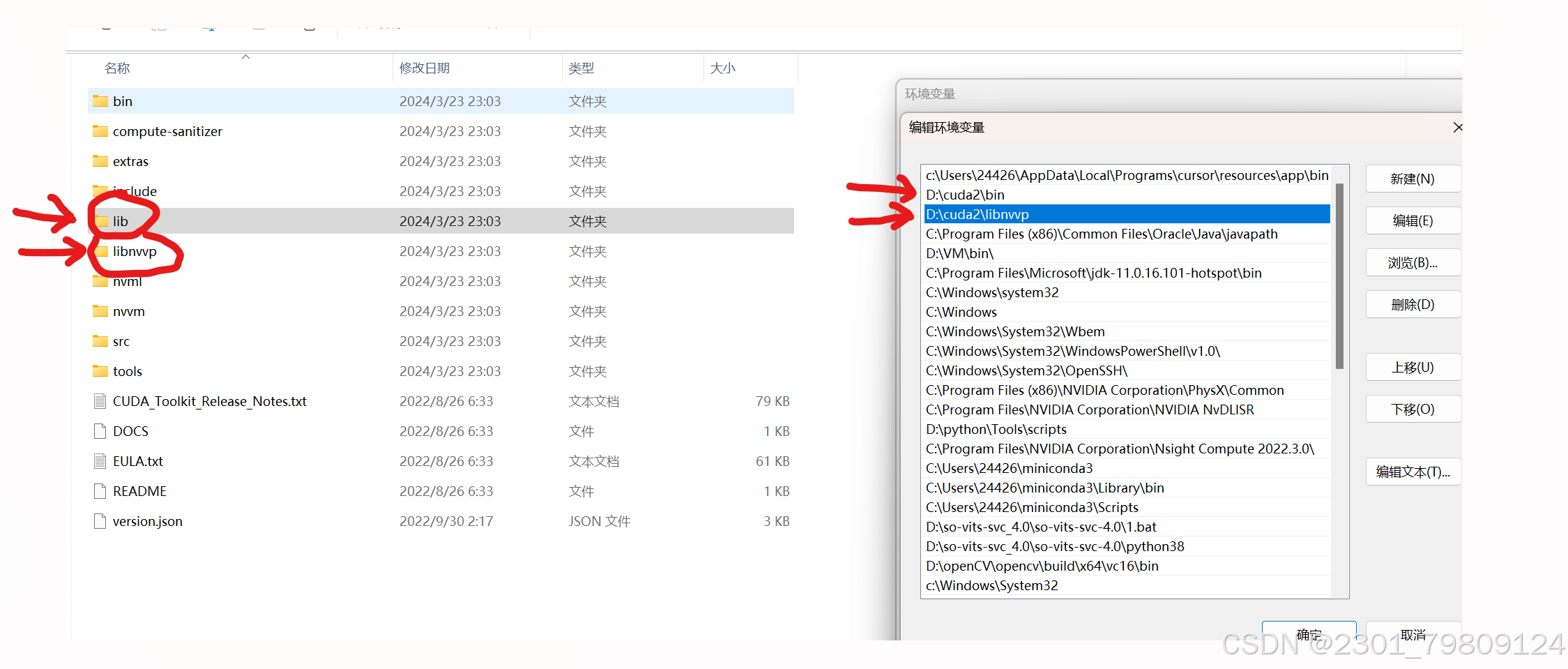
要验证是否安装成功,可以运行以下指令
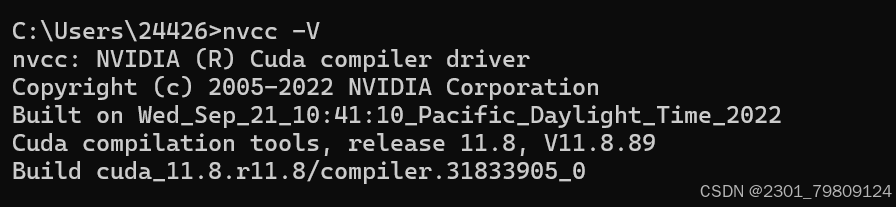
nvcc -V
正常情况下会显示这些
在nvidia官方网页可以查看每个CUDA toolkit版本对应的cudNN版本
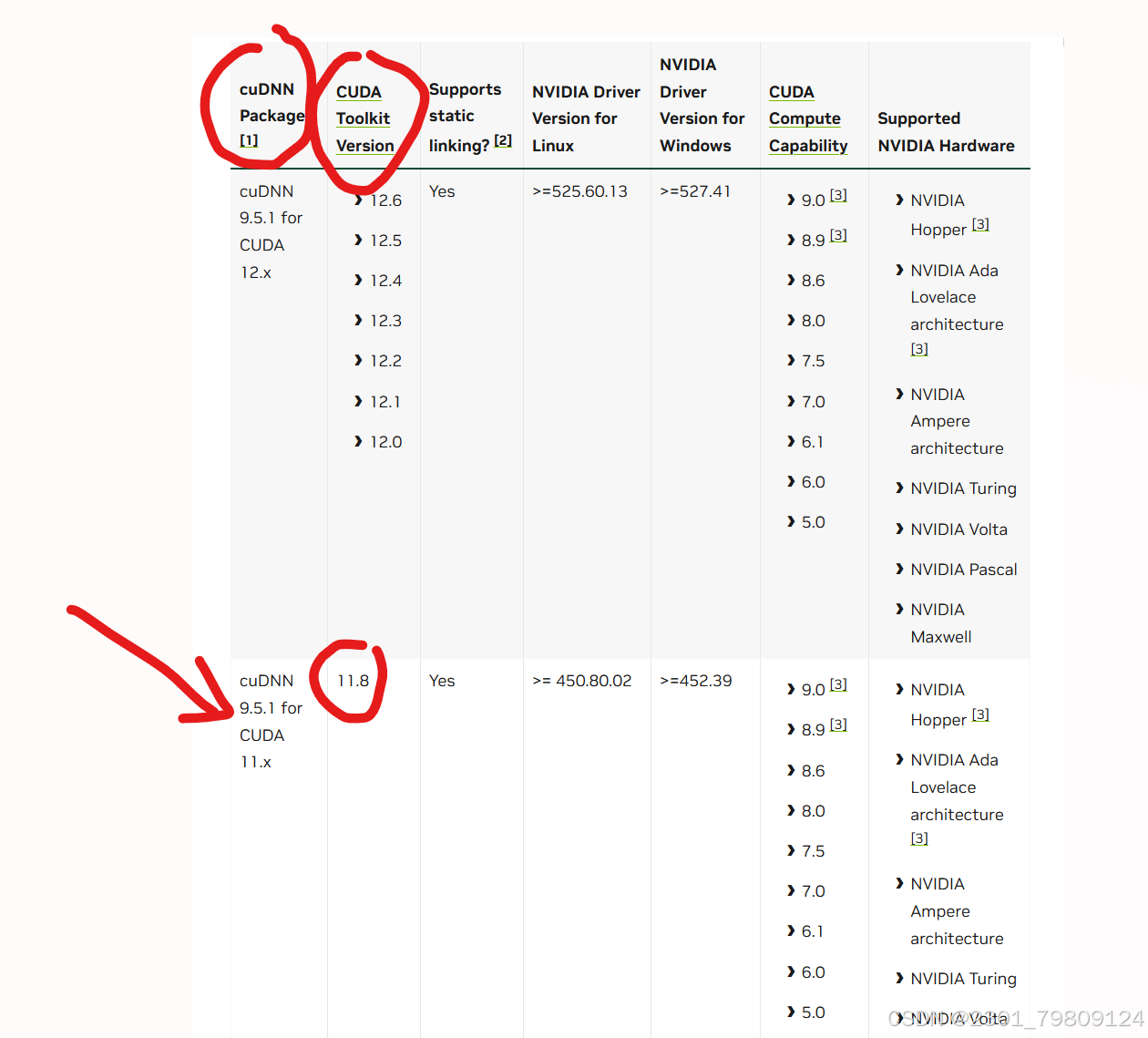
例如我下载了CUDA toolkit 11.8,对应的cuDNN 版本为 9.5.1 点击这里下载cudNN9.5.1
在这里找到每个CUDA toolkit对应的cudNN下载
注意这里可能会让你注册一个nvidia的账号,就正常的注册就行,像注册游戏账号一样
安装好之后会自动添加环境变量
如何验证我们下面再说
PyTorch 是一个流行的 深度学习框架,它是用来帮助人们更快、更方便地创建和训练神经网络模型的工具。 在人工智能和机器学习中,我们需要用复杂的数学运算来让模型从数据中“学习”。PyTorch 就是专门为这种任务设计的,它能让我们方便地使用 GPU 加速运算,让训练模型的过程更高效。而且,PyTorch 的设计让它使用起来像在写简单的 Python 代码,这让许多新手很快就能上手。
首先在控制台激活你的conda环境(不会conda环境的,或者还没有安装minconda的,看这篇文档第二部分-安装python的IDE)
请务必激活conda环境再进行下面的操作!!!
请务必激活conda环境再进行下面的操作!!!
请务必激活conda环境再进行下面的操作!!!
重要的事情说三遍,不然把pytorch装到系统环境里有你好哭的
之后进入pytorch官网,可以看到如下图的界面
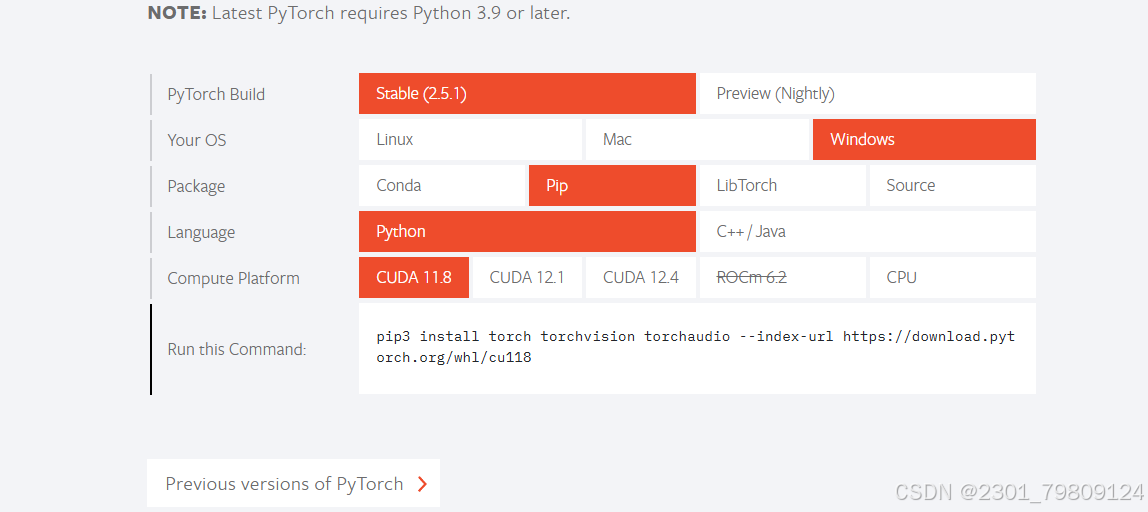
这里把11.8版本的安装命令放在这里
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
pytorch有大概5G,下载有点慢需要等一会
如何验证是否安装完成?
python
import torch
print(torch.__version__)
如下图所示就是安装完成了,会打印出你的pytorch版本号
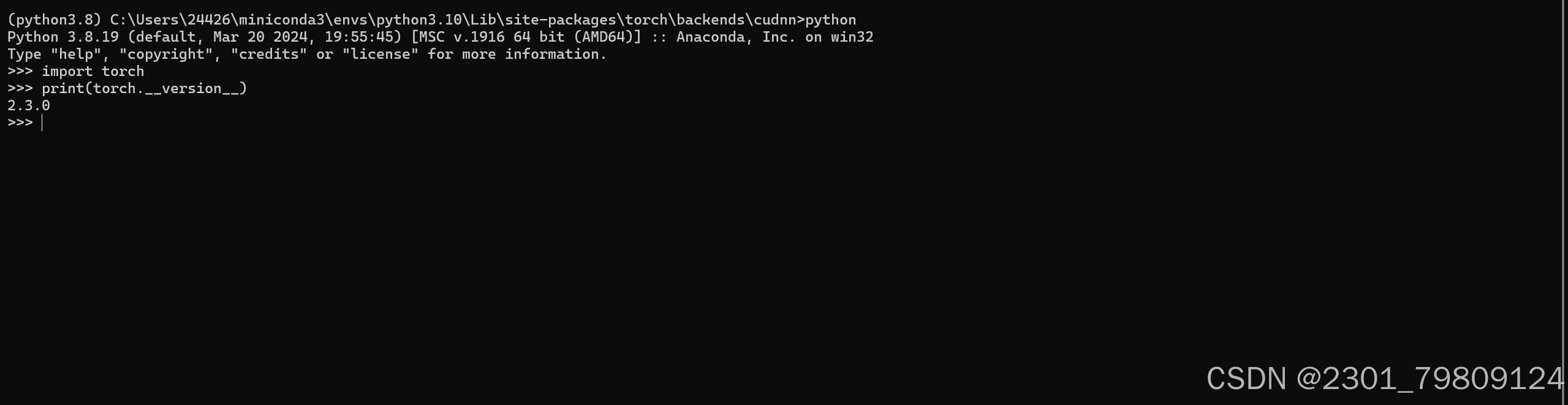
还是在上面的conda环境中,输入以下指令
python
import torch
print(torch.cuda.is_available()) # 输出 True 表示 CUDA toolkit成功匹配
print(torch.backends.cudnn.enabled) # 如果为 True 表示 cuDNN 成功匹配
然后哪里出问题了重装哪里,如果都是正确的,恭喜你,基本的深度学习环境你已经配置完成,可以开始你的第一个项目了--猫狗分类器
github地址在这里 https://github.com/Rachel1477/CNN-catvsdog
使用git可以把项目下载到你的电脑中
git clone https://github.com/Rachel1477/CNN-catvsdog.git
为了方便大家,我把数据集加入到这个项目中,无需额外下载,同时我上次训练的模型文件也在这里(Resnet34.pth)
开始训练前,请先安装依赖,在这个目录下打开控制台输入
pip install -r requirements.txt
之后就可以开始了
进入train.py,运行即可开始训练,完成后会有一张图片显示训练结果,如图
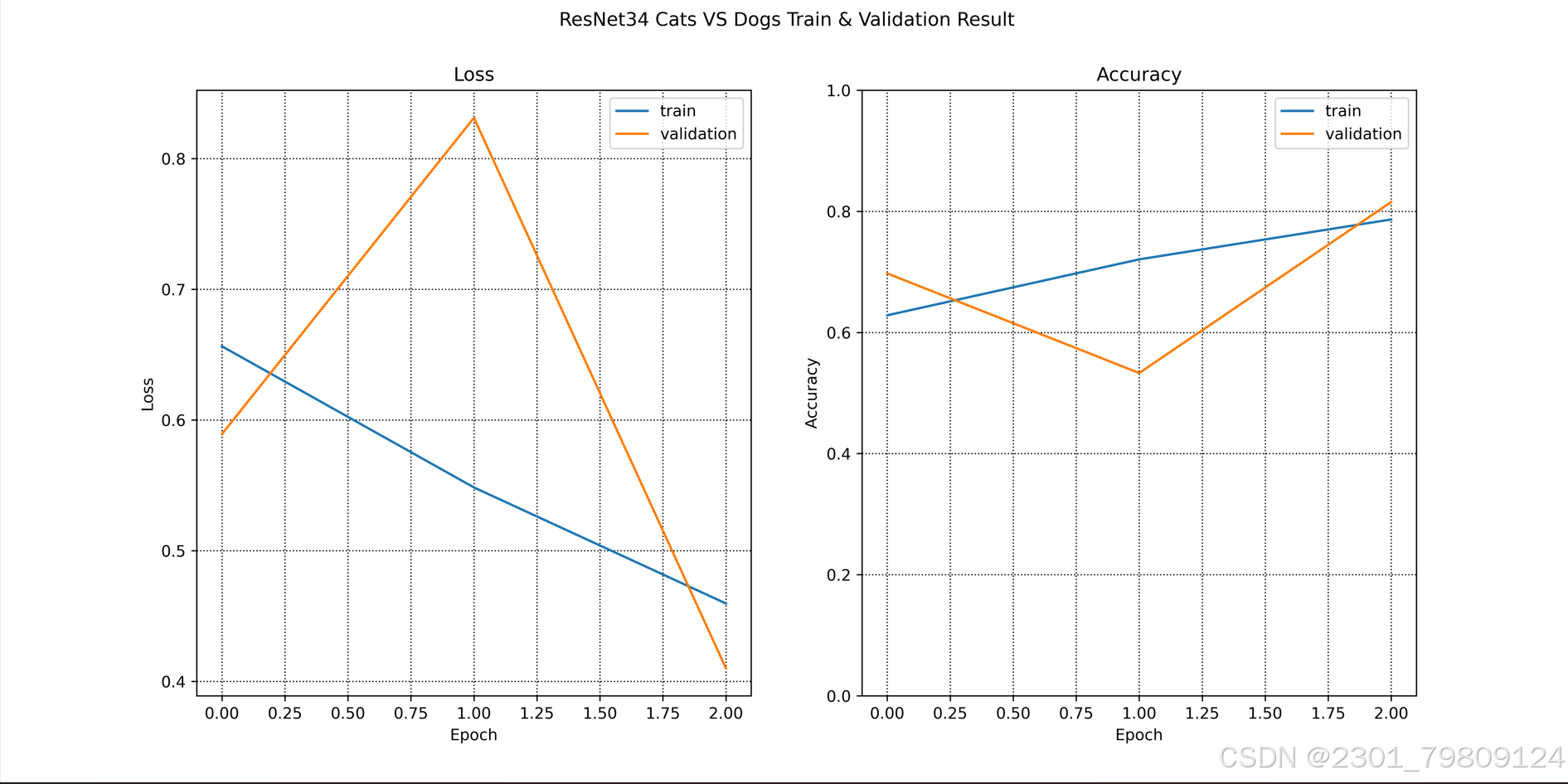
train.py中的一些参数都是可以调整的
--Epoch:表示遍历整个训练集的次数。在每个 epoch 中,模型会遍历一次全部训练数据并更新其参数。一轮训练完成后,模型会再用同一数据集重新训练,以进一步优化。更高的 epoch 数通常意味着更充分的训练,但过多可能导致模型过拟合。
--batch_size:指每次训练所使用的样本数量。将训练集分成若干批次(batch)有助于减少内存占用。较小的 batch size 会使模型更频繁地更新参数,但训练速度较慢;较大的 batch size 提升速度,但需要更多内存,并可能导致模型更易陷入局部最优解。
--Lr:学习率控制。模型参数更新的步长,值越大则参数调整幅度越大,训练速度更快,但可能不稳定;值过小则模型收敛更慢。
-- loss:是衡量模型预测结果与数据集之间差距的指标,越小表示模型给出的结果与数据集中的结果相近,当loss逐渐降低,表示模型已经基本学习完了数据集中的知识,可以停止训练了。
-- Accuracy:衡量模型好坏的基本指标,表示模型给出的预测值的准确程度,越高说明模型效果越好
这两者是不一样的,并不是loss越低,accuracy就越高,就好比虽然你完全地学习完了一本《高等数学》教材,但是老师出的题目是线性代数的题目,此时loss很低(你已经精通《高等数学》)但是你的accuracy也很低(题目中出现《高等数学》中没有的知识)
模型的好坏不仅仅取决于训练情况,还取决于数据集,测试环境,算力等很多因素
进入evaluate.py,运行即可使用模型做出预测结果,并保存在result中
理论知识看这里: https://zhuanlan.zhihu.com/p/360550845
至此,你的第一个深度学习项目就完成了,是不是很有成就感(doge)